
The purpose of this article is to share our experience with Apache Airflow implementation in order to share knowledge.
How is the data structure at Helpling?
Every company has its own way to handle its data solutions and its own logic to query/store data. At Helpling, we are following Ralph Kimball’s main Data Warehousing fundamentals.
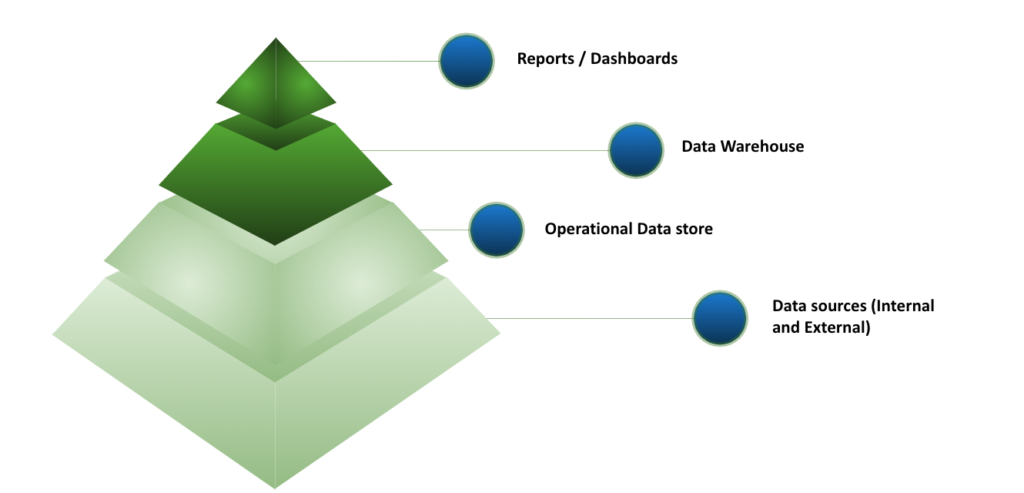
Currently, we are pushing data from several data sources to our ODS in a centralized way. Later on, we consume that data and transform it into facts and dimensions in order to store it in our DWH. Our automated reports and dashboards are mainly consuming analytics data from the Datawarehouse.
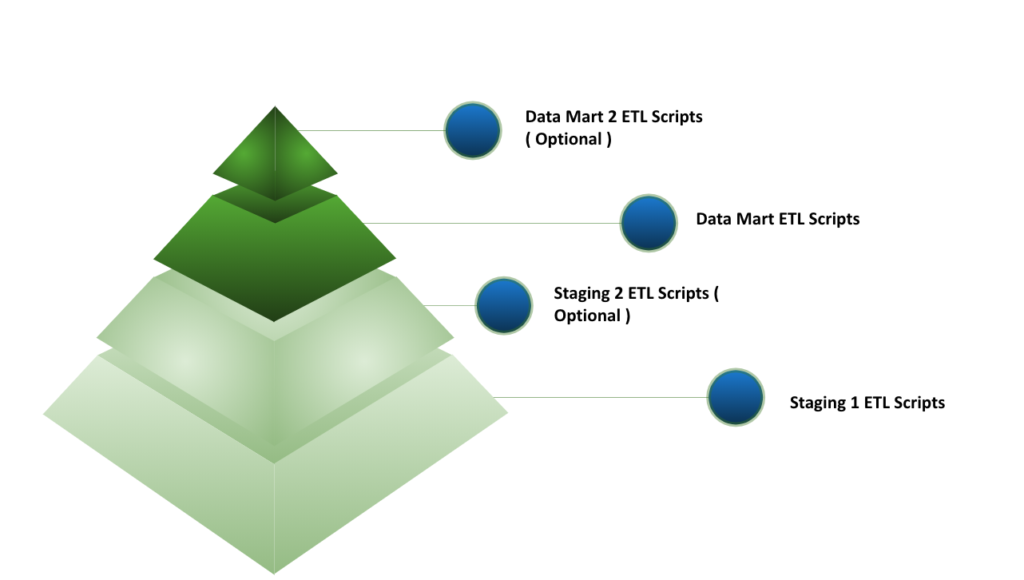
Following our data storage logic defined above, our scripts are dependency orient. Meaning, we run our scripts following the bottom-top approach for each defined workflow. As an example, Datamart scripts will not run until Staging 2 scripts and Staging 1 scripts are successfully executed.
Why Airflow?
Apache Airflow is an open-source tool for orchestrating complex computational workflows and data processing pipelines.
| ETL Project | Apache Airflow | Details |
| Script | Operator ( Task ) | Will generate a task instance and run the script |
| Workflow | DAG | Will execute the operators in the order defined using the dependency logic |
An Airflow workflow is designed as a directed acyclic graph (DAG). That means, that when authoring a workflow, you should think about how it could be divided into tasks that can be executed independently.
For these main reasons, we decided to implement Apache-Airflow as our main orchestration tool for Data pipelines processes:
- Open-source: Except for server costs and time invested in deployment, airflow is free and maintained as well for free.
- Used by many big companies, and created by Airbnb.
- Dependency oriented execution and scheduling: Troubleshooting is easier, risk management and more efficient ( speed and cost ). Dependency logic is what Data departments rely on while building ETL pipelines.
- Flexible architecture: Multiple ways to deploy it. Making it a great choice for all sized companies regardless of what infrastructure they are relying on.
- BashOperators are a plus for us here since we do not want to waste time changing our ETL scripts.
- Flexible in terms of use: In airflow, there are no best practices on how to use or in which use case Airflow will fit perfectly. It is built to be simple and flexible.
In more details, this is how we used to run our ETL pipelines scripts:
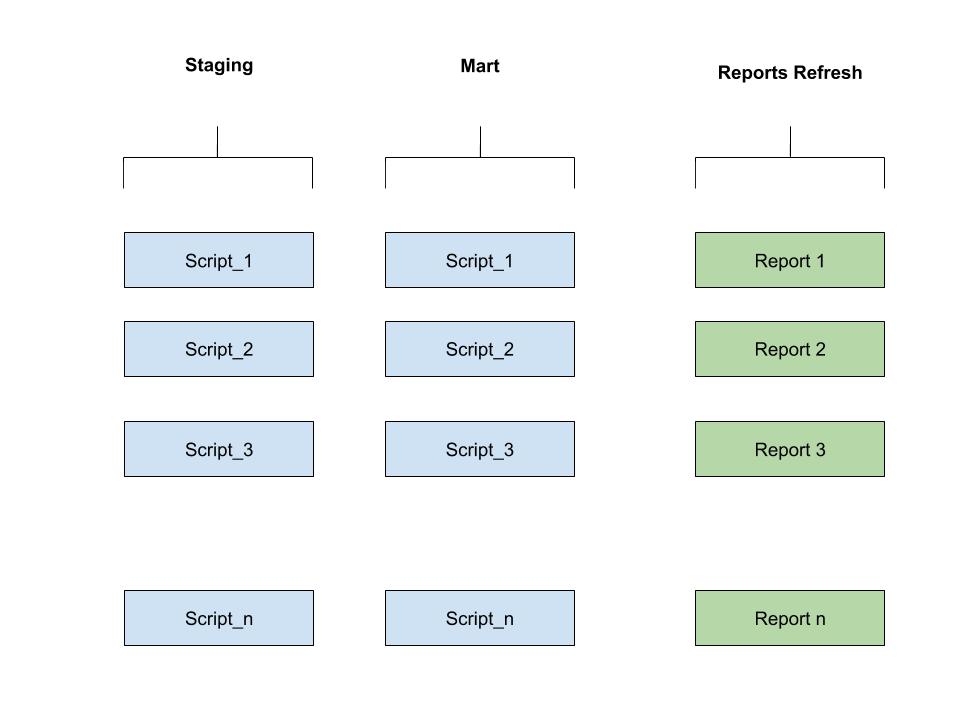
Following the old logic, we are not able to refresh any report if one script is failing in the staging phase, the same for mart scripts.
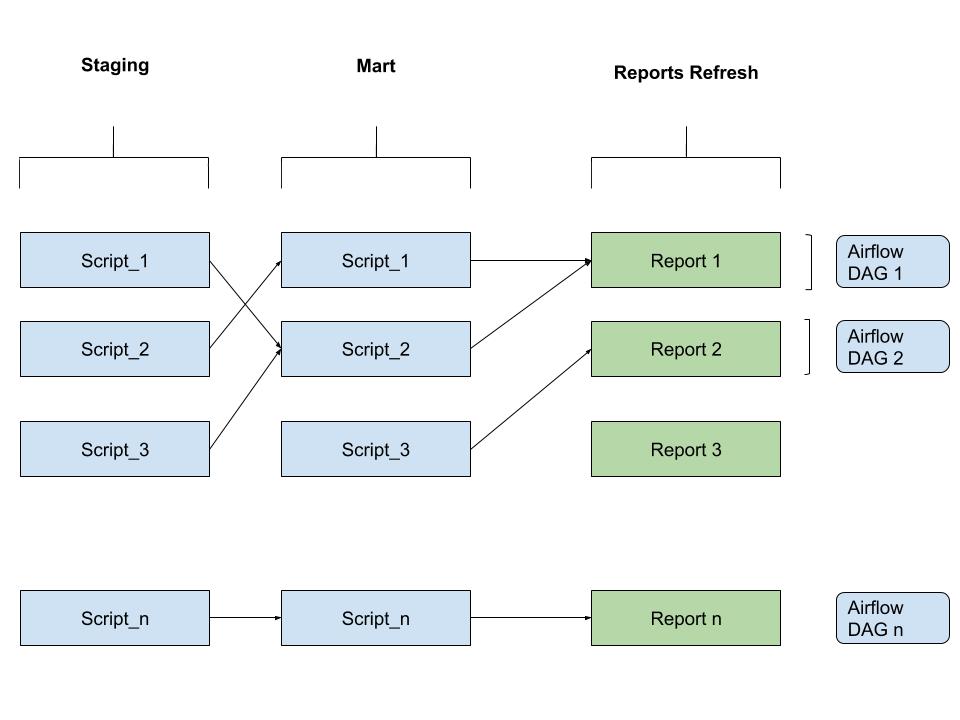
With Airflow, we are able to reflect our ETL dependency logic while executing the workflows. This way, if a staging script failed, only it is a relative report / Dashboard that will not be refreshed. Everything else will be running independently as long as it is not dependent on the same scripts.
When designing Airflow operators, it’s important to keep in mind that they may be executed more than once. Each task should be idempotent, i.e. have the ability to be applied multiple times without producing unintended consequences.
Michał Karzyński
Project Roadmap
After making sure that Airflow is a suitable solution for our business requirements, we defined the teams involved in this project, and what should we expect from each team.
In our case, we collaborated with our System engineers to have a proof of concept first. It is really important that we make sure that Airflow covers all of our needs in terms of several data sources and processes that we have to run.
Our System engineers took the time and the freedom to benchmark several deployment architectures ( Docker, AWS, Google cloud composer ) and we ended up deploying a non-centralized AWS EC2 server architecture. We will follow up with another article explaining our approach regarding server deployment.
After the Server is deployed, the business intelligence team will proceed into the proof of concept phase. Mainly we tried to test different workflows in Airflow while comparing the ease of use and the efficiency of the new server compared to what we used to have.
Main important points in the proof of concept phase :
- Git synchronization and refresh rate:
- Pushing changes on the ETL and check if Airflow is being refreshed using a reasonable time span
- Pushing new DAG / Changes on DAGs and check how fast is Airflow code refresh
- Workers are being triggered:
- Executing DAG
- Triggering operators independently
- Operators are working:
- Testing all types of operators. In our case, what we care about now is the bashOperators.
- DAG is working:
- DAG is triggering tasks as expected with proper scheduling.
- Scheduler / Workers:
- How fast is the worker in terms of executing and triggering tasks
- How fast is our scheduler? Does it start tasks immediately ? is there a delay?
- Variables and connexions
- Does airflow support all of our connexions / environment variables ?
- Does airflow support consuming back these variables through bash operators in our case?
Common issues that we faced:
- Why my variables are visible even though they are encrypted?
- This may not be intuitive, but airflow will show all of your connexions/variables defined as plain text, even though they are stored and exchanged in an encrypted way unless you name the variables with a keyword reflecting that it is a secret key or a password ( include key, pwd, password, secret in the name of the variable)
- Workers are not loaded properly ( make sure that you have at least one worker running all the time )
- Following our current EC2 Architecture, our workers are not on the same server as our scheduler instance.
- If your task is stuck at the scheduled status, it is your worker that is down.
- If the worker is up, and the issue persists, check how often your scheduler and worker are exchanging the heartbeat.
- My DAG is not running:
- Unless you put the start date of your DAG definition as an anterior date to the current date, your DAG will never run.
After wrapping up the proof of concept phase, we raffinate our server requirements and communicated to our System engineers what to fix and what to improve. After the new requirements are deployed, we can safely proceed into migrating all of our ETL scripts to Airflow.